library(tidyverse)
library(lubridate)
library(RColorBrewer)
open_payments_original <- read_csv("https://raw.githubusercontent.com/sds-192-intro-fall22/sds-192-public-website-quarto/main/website/data/open_payments_ma.csv") |>
select(covered_recipient_npi,
covered_recipient_first_name:covered_recipient_last_name,
applicable_manufacturer_or_applicable_gpo_making_payment_id,
applicable_manufacturer_or_applicable_gpo_making_payment_name,
recipient_city,
recipient_state,
covered_recipient_specialty_1,
total_amount_of_payment_usdollars,
indicate_drug_or_biological_or_device_or_medical_supply_1,
product_category_or_therapeutic_area_1,
name_of_drug_or_biological_or_device_or_medical_supply_1,
date_of_payment,
nature_of_payment_or_transfer_of_value,
number_of_payments_included_in_total_amount,
form_of_payment_or_transfer_of_value,
dispute_status_for_publication,
payment_publication_date) |>
filter(!is.na(covered_recipient_npi))Lab 8: Programming with Data
Introduction
In this lab, we will program some custom R functions that allow us to analyze data related to medical conflicts of interest. Specifically, we will determine which ten Massachusetts-based doctors received the most money from pharmaceutical or medical device manufacturers in 2021. Then we will leverage our custom functions to produce a number of tables and plots documenting information about the payments made to each of these doctors. In doing so, we will update a similar analysis produced by ProPublica in 2018 called Dollars for Docs.
Learning Goals
- Write custom
Rfunctions - Iterate a function over the values in a vector, using the family of map functions
- Practice data cleaning and wrangling
Review of Key Terms
Tip
You may wish to reference this purrr Cheatsheet when completing this lab.
- Function
-
a series of statements that returns a value or performs a task
- Iteration
-
repeating a task over a series of values, vectors, or lists
CMS’s Open Payments Dataset
In 2010, the the Physician Payments Sunshine Act (2010) was passed, requiring medical drug and device manufacturers to disclose payments and other transfers of value made to physicians, non-physician practitioners, and teaching hospitals. This law was put into place to promote transparency in our medical system - enabling the U.S. government and citizens to monitor for potential medical conflicts of interest.
Today, every time a drug or medical device manufacturer makes a payment to a covered recipient, they must disclose the nature of that payment and the amount to the U.S. Centers for Medicare & Medicaid. Data about payments is then aggregated, reviewed by (and sometimes disputed by) recipients, corrected, and then published as an open government dataset.
Definitions for what counts as a reporting entity, a covered recipient, and a reportable activity have been expanding since the passing of the Physician Payments Sunshine Act as legislators have raised concerns over the degree of transparency of diversifying financial arrangements in the healthcare system. In 2020, the first settlement for violations to the Sunshine Act was announced, requiring Medtronic Inc. to pay $9.2 million to resolve allegations for failure to report. This served as a signal that enforcement is ramping up in the coming years. In 2022, the state of California passed a law requiring that medical practitioners disclose to patients that this data resource exists.
Setting Up Your Environment
- Run the code below to load today’s data frames into your environment.
Cleaning up this Data Frame
Eventually we are going to plot some timelines of payments to specific doctors, and we will need the date_of_payment column to be in a date-time format to do so. Right now however, these columns are strings. To get started with cleaning up this dataset, let’s convert the date columns in open_payments_original to a date-time format.
Question
Write code to convert the date_of_payment and the payment_publication_date column to date-time format. You should first determine the format of the date in date_of_payment and payment_publication_date and then reference the lubridate to determine the corresponding function for parsing that date format. Finally, you will mutate the two columns.
Optional challenge: Rather than mutating each column, see if you can
mutate()across()the two columns to complete this step.
# Uncomment below to write code to convert to date-time format here.
# open_payments_dates_cleaned <- open_payments_original |>To confirm that we’ve done this right, we can check whether both of the dates are in the date-time format.
Question
The is.Date function returns TRUE if a vector is in date-time format, and FALSE if it is not. Below, I’ve selected the two columns in open_payments that contain the word “date” in the column header. Determine which map() function to use in order to return a vector that indicates whether these columns are in a date-time format. If you’ve done everything correctly, you should get the output below.
# Select the appropriate map function below
open_payments_dates_cleaned |>
select(contains("date")) |>
_____(is.Date) date_of_payment payment_publication_date
TRUE TRUE
Tip
Check out what happens if you swap out your map function above for map, map_chr, or map_int. Can you figure out the relationship between these values and the original values?
It’s important to note that the unit of observation in this dataset is not one medical practitioner, and it is not one manufacturer. Instead it is one payment from a manufacturer to a medical practitioner. That means that a medical practitioner can appear multiple times in the dataset if they’ve received multiple payments, and a medical drug or device manufacturer can appear multiple times in the dataset if they’ve disbursed multiple payments. We can identify medical practitioners with the covered_recipient_npi column and manufacturers with the applicable_manufacturer_or_applicable_gpo_making_payment_id column.
…but we want to know more than just the ID of a medical practitioner. To identify which doctors are receiving the most money, we also want to know that practitioner’s name, location, specialty, etc. Because practitioners’ names are manually entered into a database every time a payment is made to them, sometimes the formatting of a practitioner’s name entered for one payment can differ from how that same practitioner’s name is formatted when entered for another payment. The same goes for other variables related to that practitioner. For instance, check out how the capitalization differs for the practitioner below. In some cases, there is a middle initial, while in others, there is a full middle name; in some cases, the practitioner’s name is all capitalized, and in other cases it is not.
open_payments_dates_cleaned |>
filter(covered_recipient_npi == 1003040676) |>
select(covered_recipient_first_name, covered_recipient_middle_name, covered_recipient_last_name)This issue with formatting exists across this entire dataset. To ensure that similar entities appear in the right buckets when we aggregate the data, we are going to standardize capitalization across the whole dataset. We’re also going to leave out the practitioner’s middle initial since it is not always included (or included in the same way).
Question
Write code to mutate across all character columns such that strings in these columns are converted to title case. Title case refers to casing where the first letter in each word is capitalized and all other letters are lowercase. Strings can be converted to title case with the function str_to_title.
After you’ve done this, mutate a new column called covered_recipient_full_name that concatenates (hint: i.e. paste()) together covered_recipient_first_name and covered_recipient_last_name.
Store the resulting data frame in open_payments.
# Uncomment below to clean up strings
# open_payments <- open_payments_dates_cleaned |>As we saw before, one covered_recipient_npi was associated with multiple names if the names were capitalized in some cases and not others. Now that we’ve standardized the formatting of these names, there ideally should be one full name associated with every covered_recipient_npi. Let’s compare the length of unique covered_recipient_npi values to the length of unique covered_recipient_full_name values to check whether this is the case.
Question
Write a function below called num_unique. The function should calculate the length of unique values in the vector passed to the argument x.
Below, I’ve selected the two columns in open_payments that we want to iterate this function over. Determine which map() function to use in order to return a numeric vector that indicates the length of unique values in each of these columns. If you’ve done everything correctly, you should get the output below.
num_unique <- function(x) {
# Write function here.
}
open_payments |>
select(covered_recipient_npi, covered_recipient_full_name) |>
_____(_____) # Determine which map function to call here. covered_recipient_npi covered_recipient_full_name
11837 11858 Notice that there are still more full names than covered_recipient_npis, which means that certain doctors have multiple names in this dataset. Below I’ve written some code to calculate the number unique full names listed for each covered_recipient_npi and filter to the rows with more than one name. Can you identify some reasons why we might have multiple names listed for this same medical practitioner in this data frame?
open_payments |>
group_by(covered_recipient_npi) |>
mutate(num_names = length(unique(covered_recipient_full_name))) |>
ungroup() |>
filter(num_names > 1) |>
select(covered_recipient_npi, covered_recipient_full_name) |>
distinct() |>
arrange(desc(covered_recipient_npi))Because of these issues, it is important that we use the covered_recipient_npi to identify doctors vs. the full name.
Now that we have a final cleaned up open_payments data frame, let’s remove the other data frames from our environment.
rm(open_payments_original, open_payments_dates_cleaned)…and on to analysis.
Data Analysis
Ultimately, our aim is to produce a number of tables and plots for each of the ten MA-based doctors that received the most money from medical drug and device manufacturers in 2021. This means that one of our first analysis steps is to identify those 10 medical practitioners.
Question
Write code to determine the 10 medical practitioners that received the most money from drug and device manufacturers in 2021, and store your results in top_10_doctors. Your final data frame should have 10 rows and columns for covered_recipient_npi and sum_total_payments.
# Uncomment below and write data wrangling code
#top_10_doctors <- open_payments |>Right now the values that we will eventually want to iterate over in our analysis are stored as columns in a dataframe. …but remember that the family of purrr functions allows us to apply a function to each element of a vector or list. We want to create a series of vectors from these columns that we can iterate over. We will use the pull() function to do this.
Question
Create a vector of top_10_doctors_ids from top_10_doctors, using the pull() function.
# Uncomment and write code below to pull the top 10 doctor IDs into a vector
# top_10_doctors_ids <- top_10_doctors |>We also want a vector of doctor names associated with each of these IDs, but remember that there can be multiple names for a single doctor in this dataset. With this in mind, we are going to create a vector of the first listed name for a given covered_recipient_npi in the dataset. Taking the first listed name as the doctor’s name is an imperfect solution. The first listed name could be a misspelling. It could be a doctor’s maiden name that they have since changed. This is a temporary solution, and we would want to confirm that we have the correct name for each doctor before publishing any of these findings.
Question
Create a vector containing the names of the doctors associated with the IDs in top_10_doctors_ids. First, define the function get_doctor_name. This function will:
- take a
doctor_idas an argument, - filter
open_paymentsto that ID, - summarize the
first()covered_recipient_full_namelisted for that ID, pull()the name value
Once this function has been defined, select the appropriate map() function to iterate top_10_doctors_ids through get_doctor_name and store the resulting character vector in top_10_doctors_names.
get_doctor_name <- function(doctor_id){
# Write function code here
}
# Iterate the top_10_doctors_ids vector through get_doctor_name and store the results in a character vector
# top_10_doctors_names <- Now that we have the vectors we want to iterate over, we are ready to start defining our first functions.
What kind of payments did MA-based doctors receive in 2021?
To get started, let’s define a function that filters open_payments to a given doctor ID, and then calculates how much of each kind of payment has been paid to that doctor. Here is an example of what that data wrangling code would look like for a specific covered_recipient_npi:
open_payments |>
filter(covered_recipient_npi == 1194763482) |>
group_by(nature_of_payment_or_transfer_of_value) |>
summarize(num_payments =
sum(number_of_payments_included_in_total_amount),
total_payments = sum(total_amount_of_payment_usdollars))Question
Wrap the above code in a function named calculate_payment_type_amts. Rather than filtering to 1194763482, filter based on the value passed to an argument named doctor_id.
Then, use the map() function to apply calculate_payment_type_amts to each element in the top_10_doctors_ids vector. Running this code should return a list of 10 data frames.
Finally, pipe in set_names(top_10_doctors_names) to set the names for each data frame in the list to the doctor’s name.
# Write calculate_payment_type_amts function here
# Iterate calculate_payment_type_amts over top_10_doctors_ids and set names to top_10_doctors_namesWhen were payments made to each of these doctors in 2021?
Here’s an example of a plot we could create to answer this question for one doctor.
open_payments |>
filter(covered_recipient_npi == 1194763482) |>
ggplot(aes(x = day(date_of_payment),
y = "",
fill = total_amount_of_payment_usdollars)) +
geom_jitter(pch = 21, size = 2, color = "black") +
theme_minimal() +
labs(title = "David Friedman",
y = "",
x = "Day",
fill = "Payment Amount") +
scale_y_discrete(limits = rev) +
scale_fill_distiller(palette = "BuPu", direction = 1, labels = scales::comma) +
facet_wrap(vars(month(date_of_payment, label = TRUE)), nrow = 4) 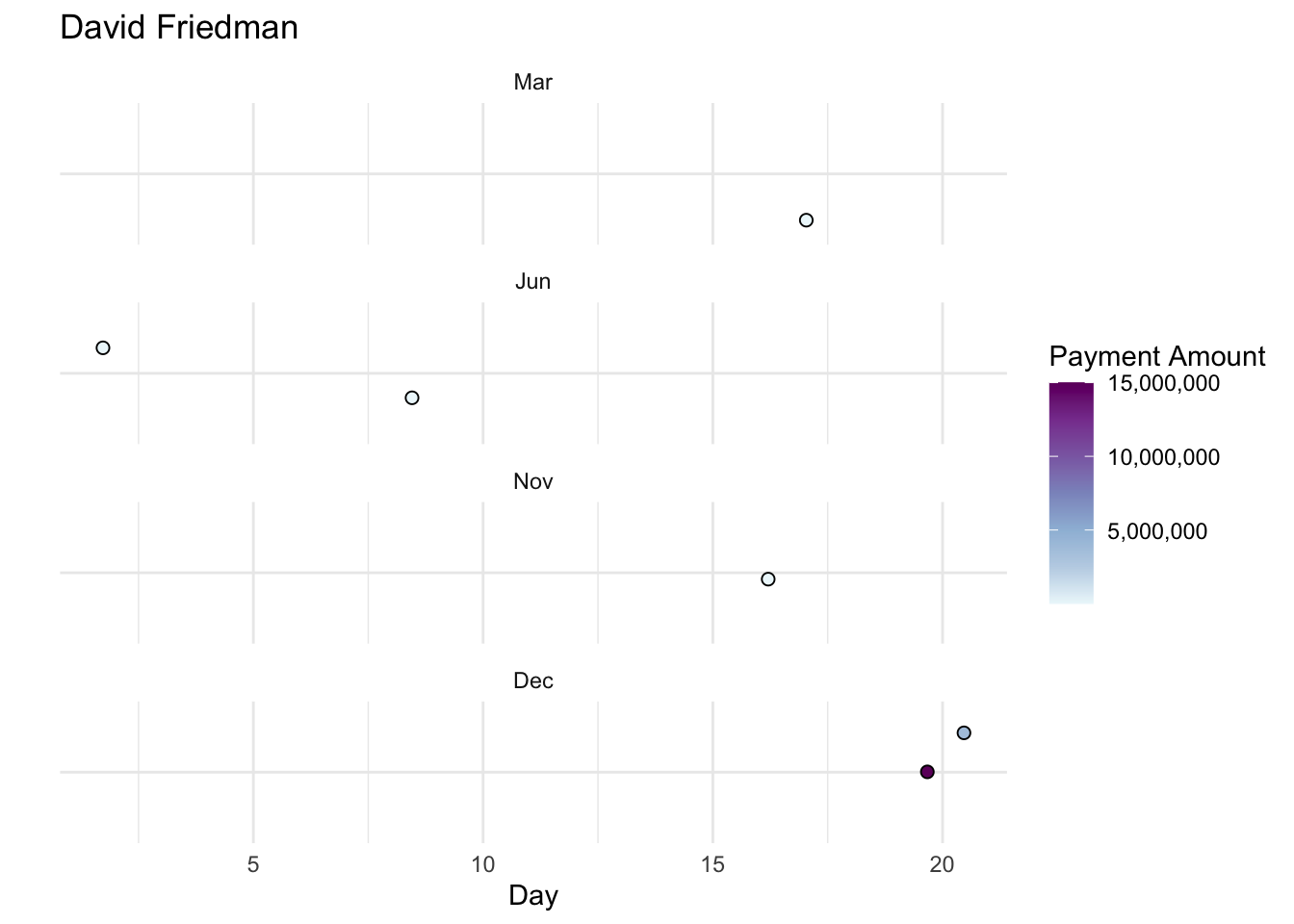
Question
Write a function named payments_calendar. The function should:
- Take a
doctor_idanddoctor_nameas arguments - Filter
open_paymentsto the doctor’s ID - Create payment calendar plot modeled after the one above.
- Set the title of the plot to the doctor’s name
After you’ve written this function, select the appropriate map function to apply payments_calendar to each element in the top_10_doctors_ids vector and top_10_doctors_names vector.
Optional Challenge: Extend your code to include the first listed specialty for each top 10 doctor as a subtitle in each plot.
# Write payments_calendar function here
# Iterate payments_calendar over top_10_doctors_ids and top_10_doctors_ids to create 10 plotsWhich manufacturers paid MA-based doctors in 2021, and through what forms of payment?
Finally, let’s define a function that filters open_payments to a given doctor ID and determines how much the doctor received in compensation from different manufacturers, along with the forms of payment from each manufacturer. To do so, we will need to aggregate the data by covered_recipient_npi, applicable_manufacturer_or_applicable_gpo_making_payment_name, and form_of_payment_or_transfer_of_value and calculate the total payments associated with each grouping.
Question
Write a function named calculate_manufacturer_payments. The function should:
- Take a
doctor_idas an argument - Filter
open_paymentsto that ID - Aggregate the filtered data by
covered_recipient_npi,applicable_manufacturer_or_applicable_gpo_making_payment_name, andform_of_payment_or_transfer_of_value - Calculate the total amount of payments for each grouping
- Sort the resulting data frame in descending order by the total amount of payments.
After you’ve written this function, use the map_df() function to apply calculate_manufacturer_payments to each element in the top_10_doctors_ids vector. Note how this returns one data frame rather than a list of 10 data frames.
Plot your resulting data frame as a column plot, attempting (to the best of your ability) to match the formatting of the plot below.
Optional Challenge: List the doctor’s full name in each facet band, rather than the the doctor’s ID.
# Write calculate_manufacturer_payments function here
# Iterate calculate_manufacturer_payments over top_10_doctors_ids here
# Plot resulting data frame here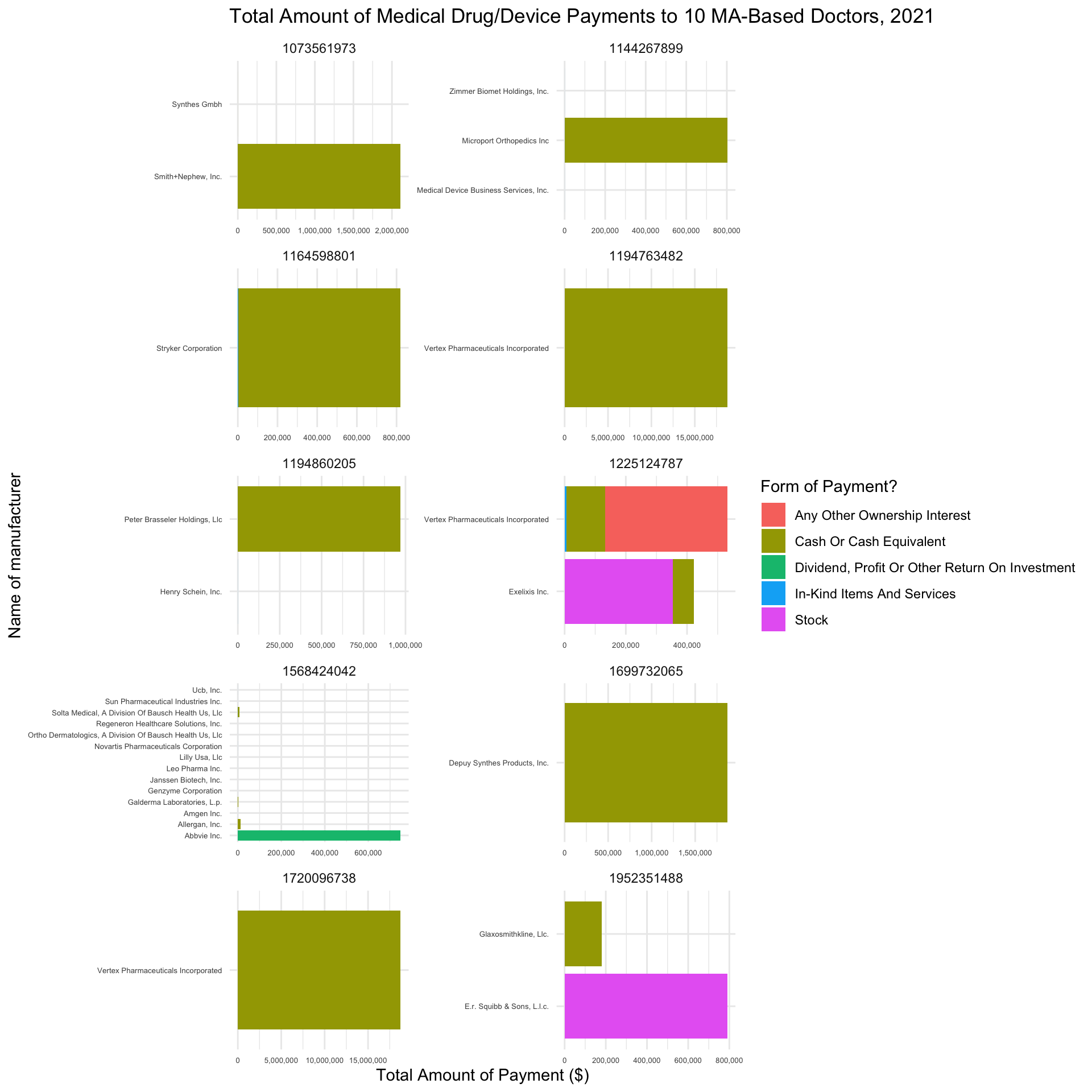
Ethical Considerations
On September 29, 2022, California Governor Gavin Newsom signed a bill requiring that all physicians and surgeons notify patients about the Open Payments database on their initial visit. Specifically, patients will be given the following notice: “The Open Payments database is a federal tool used to search payments made by drug and device companies to physicians and teaching hospitals. It can be found at https://openpaymentsdata.cms.gov,” and will be prompted to sign and date that they have received the notice. This policy was developed in response to concerns that, while the Open Payments database includes a great deal of information that might impact how citizens make decisions about their healthcare, very few people knew of the database. Do you think this is a good solution to this problem? Should other states follow suit? Do you see any drawbacks to this policy? Share your ideas on our sds-192-discussions Slack channel.