Data Wrangling
SDS 192: Introduction to Data Science
Lindsay Poirier
Statistical & Data Sciences, Smith College
Fall 2022

For Today
- Quiz 1
- Subsetting Data
- Aggregating Data
- Activity
Data wrangling is a process for transforming a dataset from its original form into a more relevant form.
Six “verbs” for data wrangling
arrange()select()filter()mutate()summarize()group_by()
arrange()
arrange()sorts rows according to values in a column- Defaults to sorting from smallest to largest (numeric) or first character to last character (character).
Subsetting data involves selecting relevant variables and observations for analysis. Aggregating data involves compiling and summarizing data.
Subsetting Data
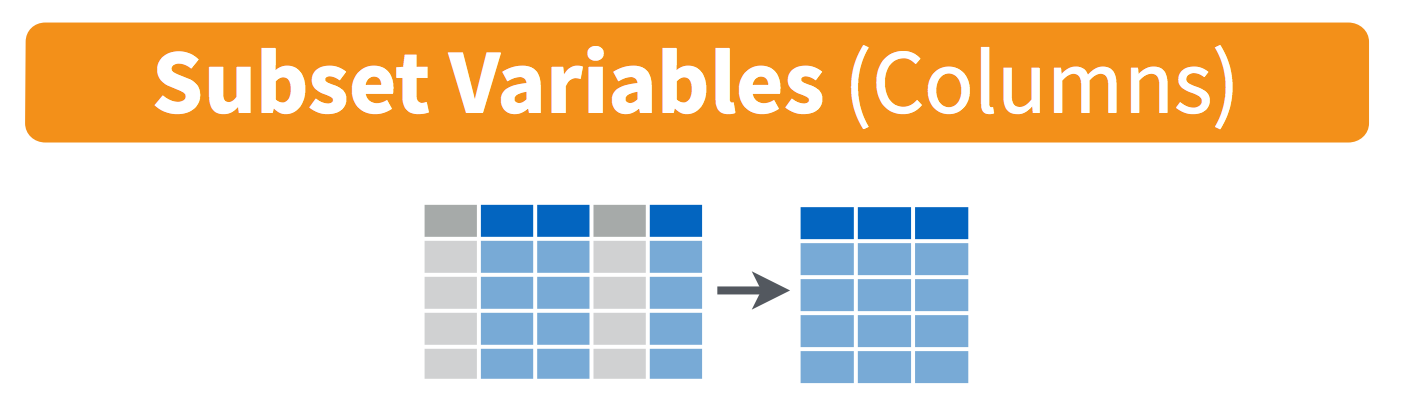
select()
select()enables us to select variables (columns) of interest.
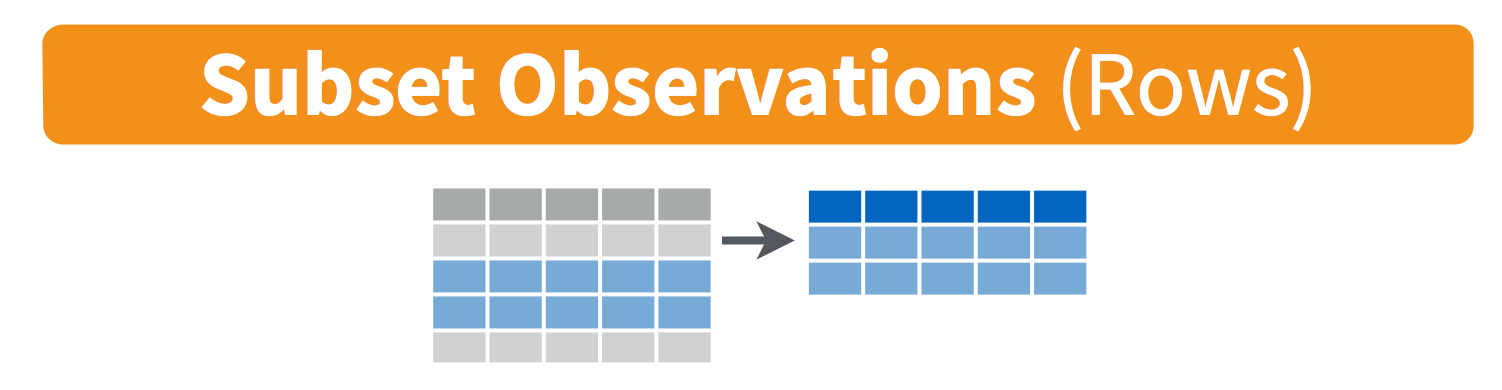
filter()
filter()subsets observations (rows) according to a certain criteria that we provide.
mutate()
mutate()creates a new variable (column) in a data frame and fills values according to criteria we provide

Aggregating Data
Summary functions

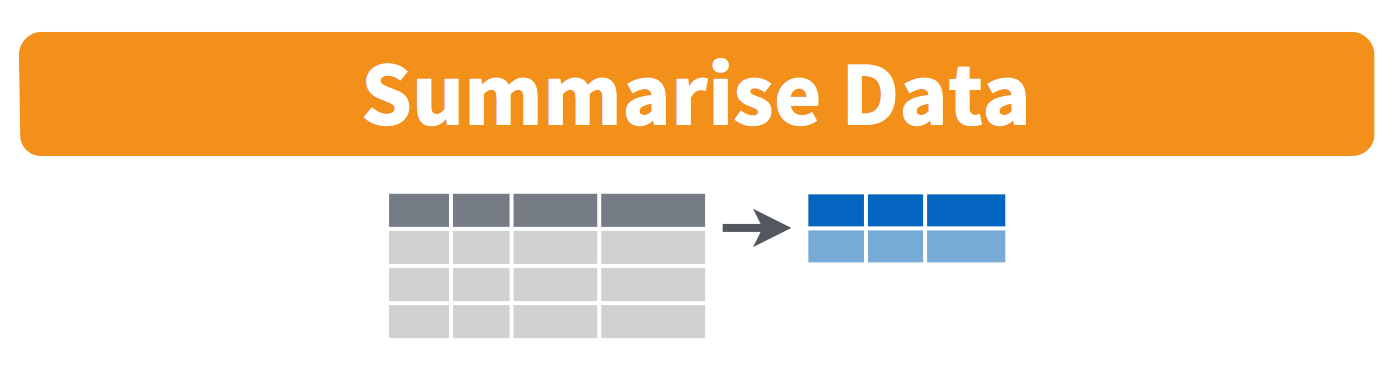
summarize()
summarize()computes a value across a vector of values and stores it in a new data frame
How is this different than only applying a summary function to a vector?
group_by()
group_by()groups observations with a shared value in a variable- Grouping only changes the metadata of a data frame; we combine
group_by()with other functions to transform the data frame - Values remain in groups unless we
ungroup()it. This is important if we intend to run further operations on the resulting data.
group_by() |> summarize()
group_by()groups observations with a shared value in a variable- When we combine
group_by()andsummarize()we can perform operations within groups
group_by() |> filter()
group_by()groups observations with a shared value in a variable- When we combine
group_by()andfilter()we can filter within groups
group_by() |> filter()
group_by() |> mutate()
group_by()groups observations with a shared value in a variable- When we combine
group_by()andmutate()we can perform operations within groups and add the resulting variable to the data frame
What’s wrong with this code?
Which song has the duration that takes up the greatest percentage of time on any playlist?
spotify_playlists |>
group_by(playlist_name) |>
mutate(TOTAL_DURATION = sum(track.duration_ms),
PERCENT_DURATION = track.duration_ms/TOTAL_DURATION * 100) |>
filter(PERCENT_DURATION == max(PERCENT_DURATION)) |>
select(playlist_name, track.name, track.duration_ms, TOTAL_DURATION, PERCENT_DURATION) |>
head()ungroup()
spotify_playlists |>
group_by(playlist_name) |>
mutate(TOTAL_DURATION = sum(track.duration_ms),
PERCENT_DURATION = track.duration_ms/TOTAL_DURATION * 100) |>
ungroup() |>
filter(PERCENT_DURATION == max(PERCENT_DURATION)) |>
select(playlist_name, track.name, track.duration_ms, TOTAL_DURATION, PERCENT_DURATION) |>
head()